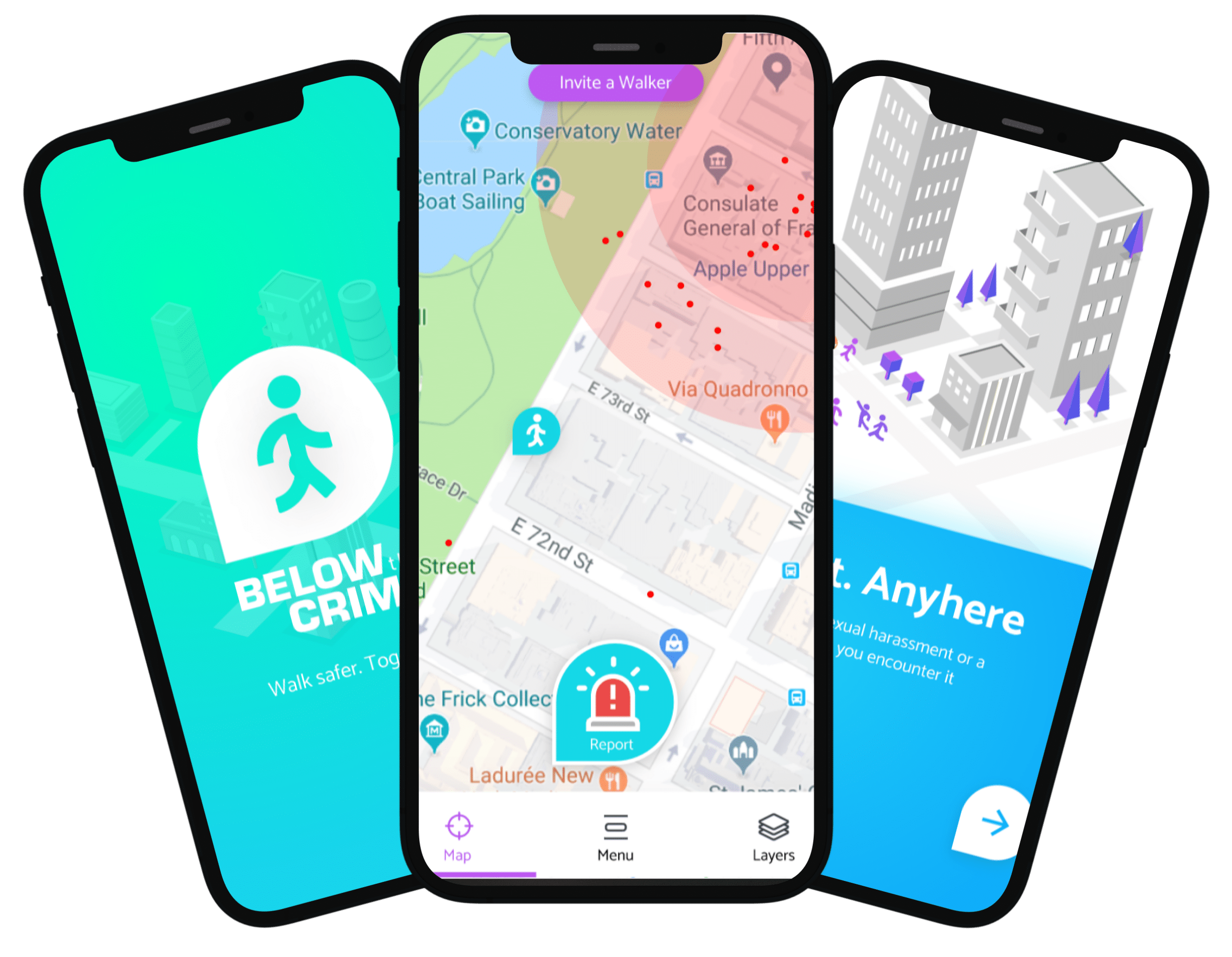
The Challenge
What Below The Crime Was Facing
Below The Crime aggregated crime statistics from public data sources across multiple jurisdictions — police force open data APIs, court records feeds, and Home Office statistical releases — each published in different formats (CSV, XML, JSON, PDF tables), on different schedules, and using different crime classification taxonomies. Building meaningful cross-jurisdictional analysis was impossible without a normalisation layer, and without one, the platform could only display raw source data with no comparative capability.
The Solution
What We Built
We built a multi-source data ingestion pipeline with per-source extractors handling format parsing, schedule management, and change detection — only re-processing sources when content had actually changed to avoid unnecessary load. A taxonomy mapping engine translated each jurisdiction crime classification into a canonical crime category model, with explicit handling for categories that had no clean mapping — flagged for analyst review rather than silently discarded. A reconciliation layer aligned temporal and geographic boundaries across jurisdictions so that aggregate statistics were comparing like for like. The processed data fed an analytical API used by the platform front end.
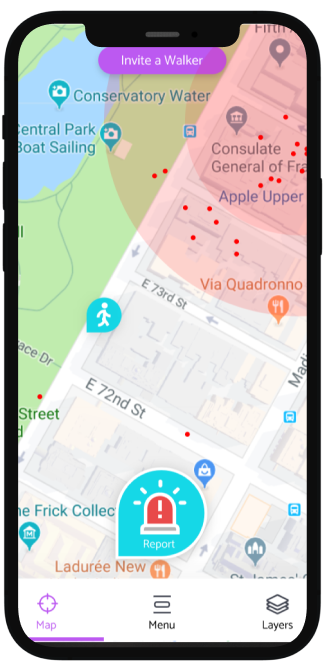
Results